Gnoppix AI PlayGround
Gnoppix AI PlayGround
Section titled “Gnoppix AI PlayGround”The Gnoppix AI PlayGround is a member service offered by Gnoppix, a modern AI Linux Distribution with a strong focus on privacy and security. It is comparable to a GPT-like application. The difference to other GPT agents is that you can choose between almost all AI models, and you can build your own AI agent army on top. We have open-source AI models as well as the latest commercial ones, e.g., GPT-5 from OpenAI. The queries you submit are not used to train the models.
This is an easy way to use (uncensored) or the latest commercial AI at a very affordable price, all while utilizing a robust privacy stack that is difficult to find elsewhere on the internet, and trying different AI models with agents on one platform.
In order to use it, you can use BYOK (bring your own key) or use our free/paid Gnoppix Member API to test the current free LLMs with our advanced privacy features.
Local AI
Section titled “Local AI”Typically, there are three ways to run AI on your computer, putting privacy issues aside:
-
You use a traditional GPT agent or API, typically costing $20-500 per month for a subscription.
-
You use local AI, for example with Ollama, and use your own hardware. (included in Gnoppix Linux)
-
You use our Gnoppix AI API key.
There are generally four ways to use Gnoppix PlayGround GPT-like App:
Section titled “There are generally four ways to use Gnoppix PlayGround GPT-like App:”-
You can access the Gnoppix PlayGround from any device with just a browser at: https://ai.gnoppix.org
-
You can use Gnoppix PlayGround directly from Gnoppix Linux.
-
By buying credits, you get an API key that is 100% “OpenAI compatible,” which you can use anywhere on any application asking for an API key and endpoint.
-
You can use your own API keys (e.g., from Google).
App Availability (To be Determined)
Section titled “App Availability (To be Determined)”-
Gnoppix plans to release dedicated applications for various platforms:
-
Multiplatform: LibreWolf Broser Addon
-
Linux App: included in Gnoppix Linux
-
iOS App: To be determined (tbd)
-
Android App: To be determined (tbd)
-
macOS App: To be determined (tbd)
-
Windows App: To be determined (tbd)
AI Updates
Section titled “AI Updates”We’ve setup 2 sources where you never miss important AI updates
- As a Gnoppix Member Discord and just look on the #AI #News section https://discord.gg/WUuT59Fdp9
- Gnoppix Forum -> https://forum.gnoppix.org/c/ai/10
How to use you Gnoppix API Key on CoPilot?
Section titled “How to use you Gnoppix API Key on CoPilot?”Step1.)
Section titled “Step1.)”Use the PlayGround APP and login :
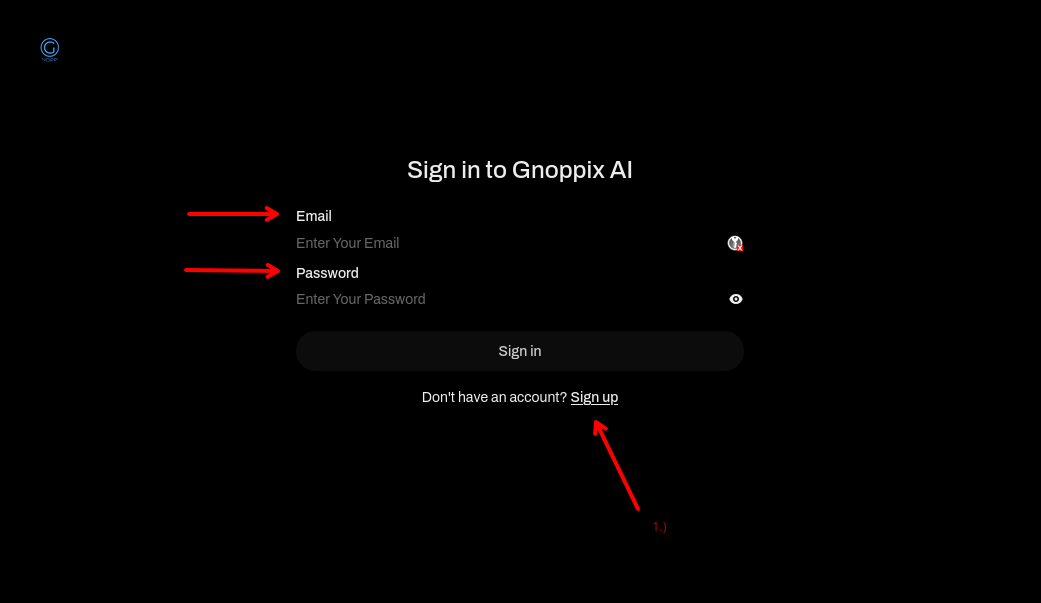
Alternatively you can use Gnoppix Browser
Step2.)
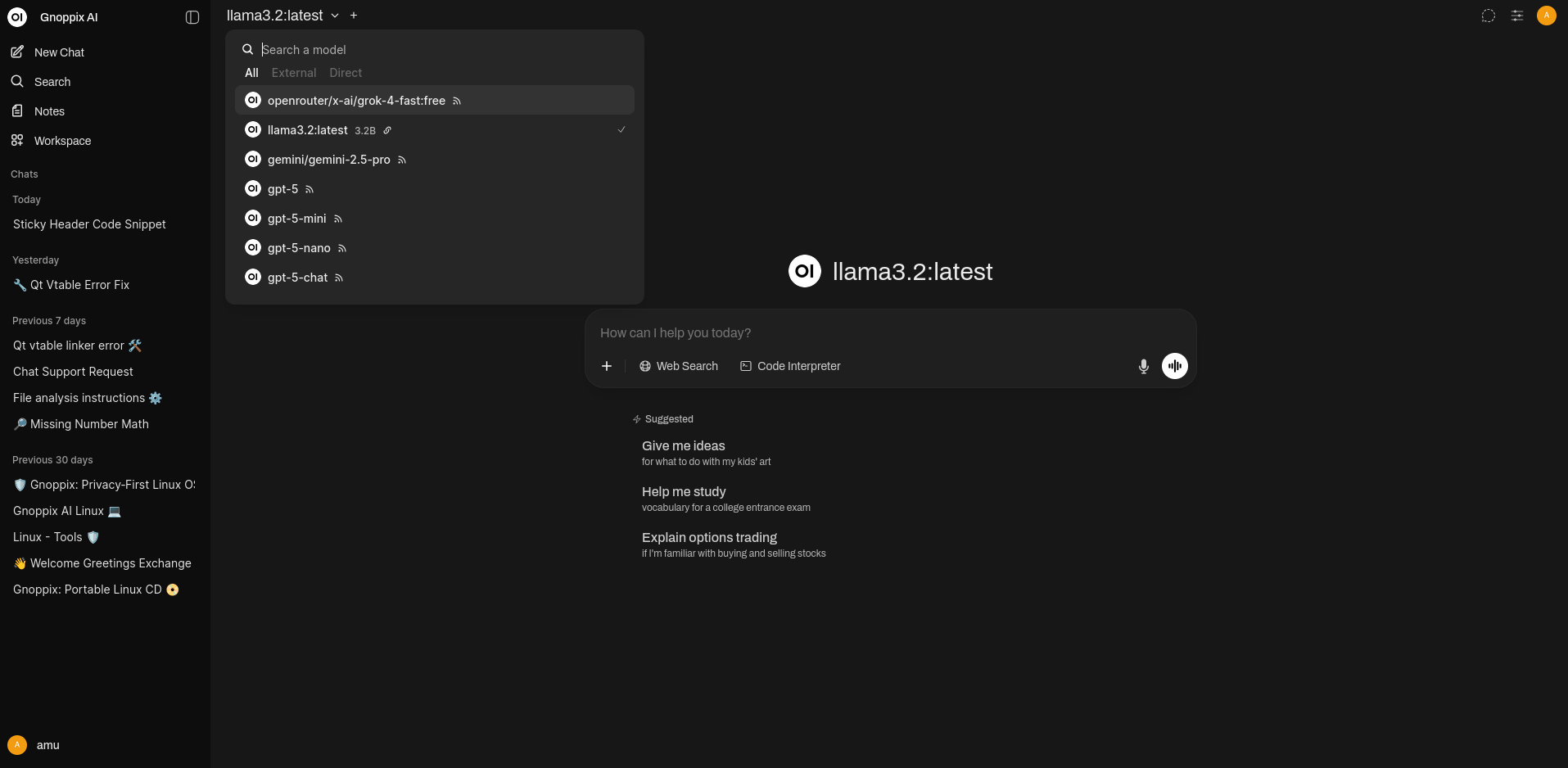
Section titled “Step2.)”Here is the guest user interface (UI).
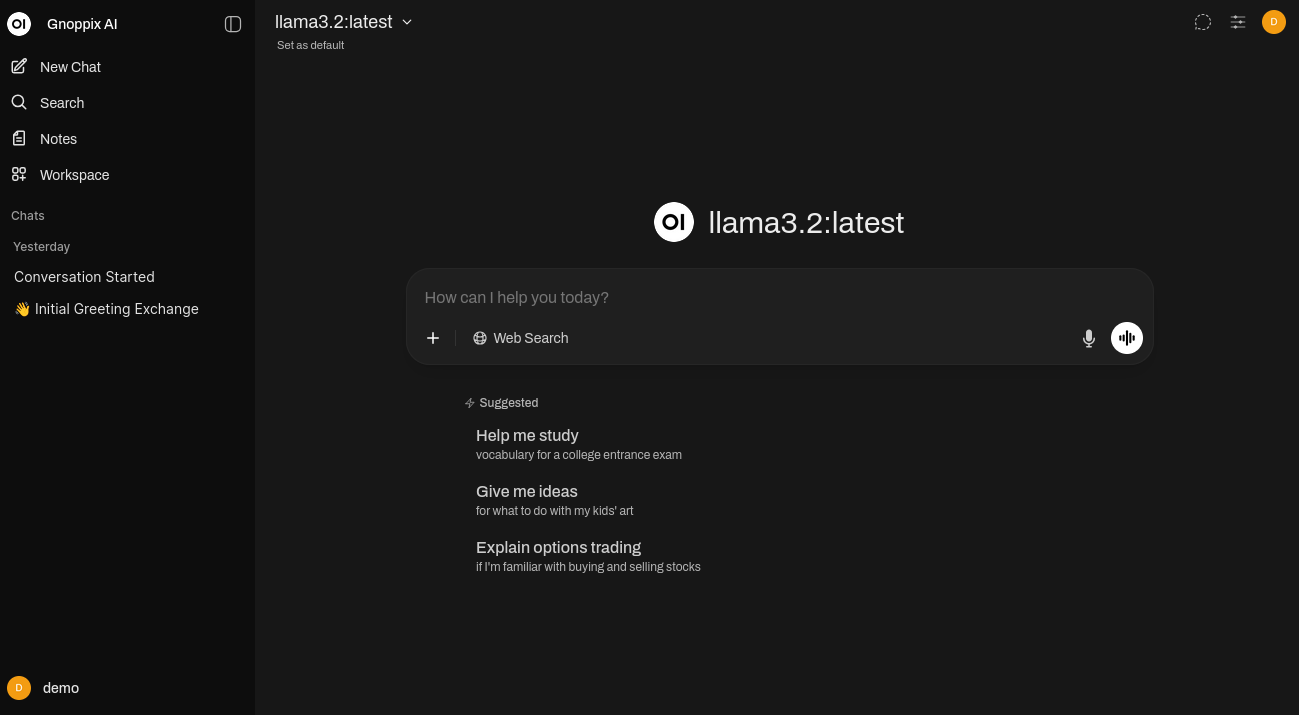
Step3)
Section titled “Step3)”Use the App as it is or add your own keys to get more models.
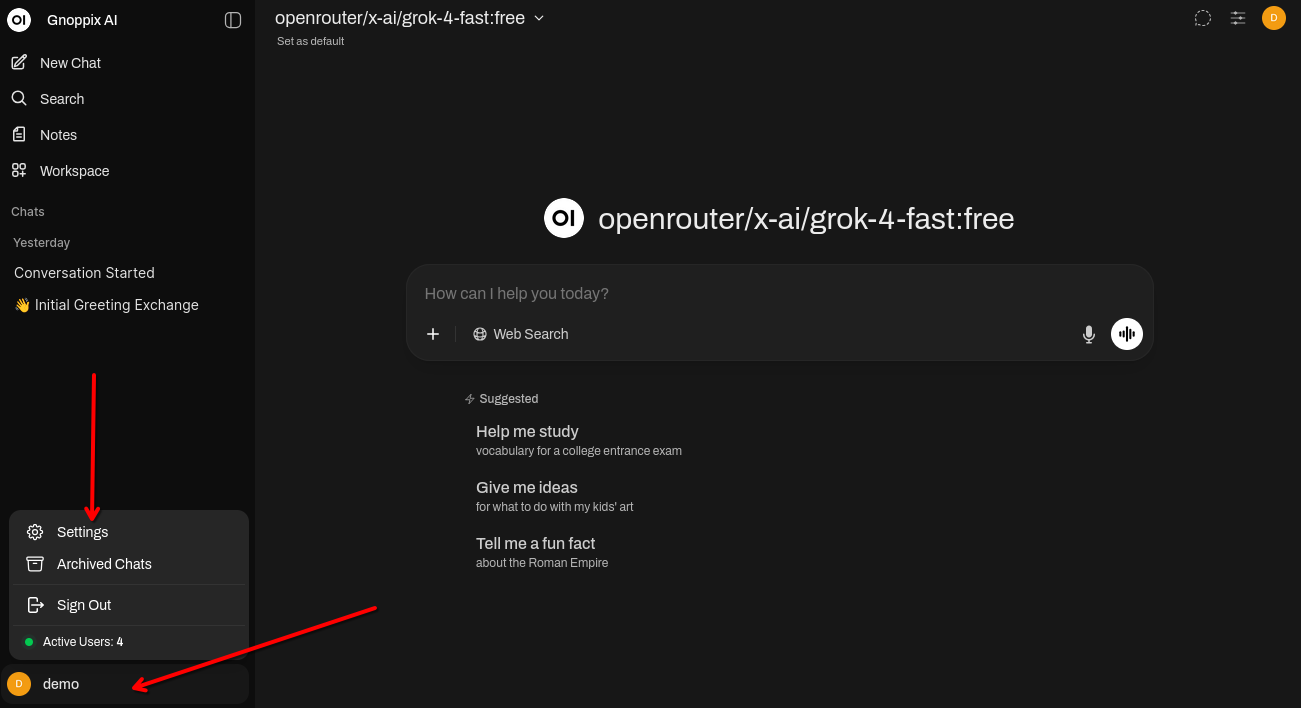
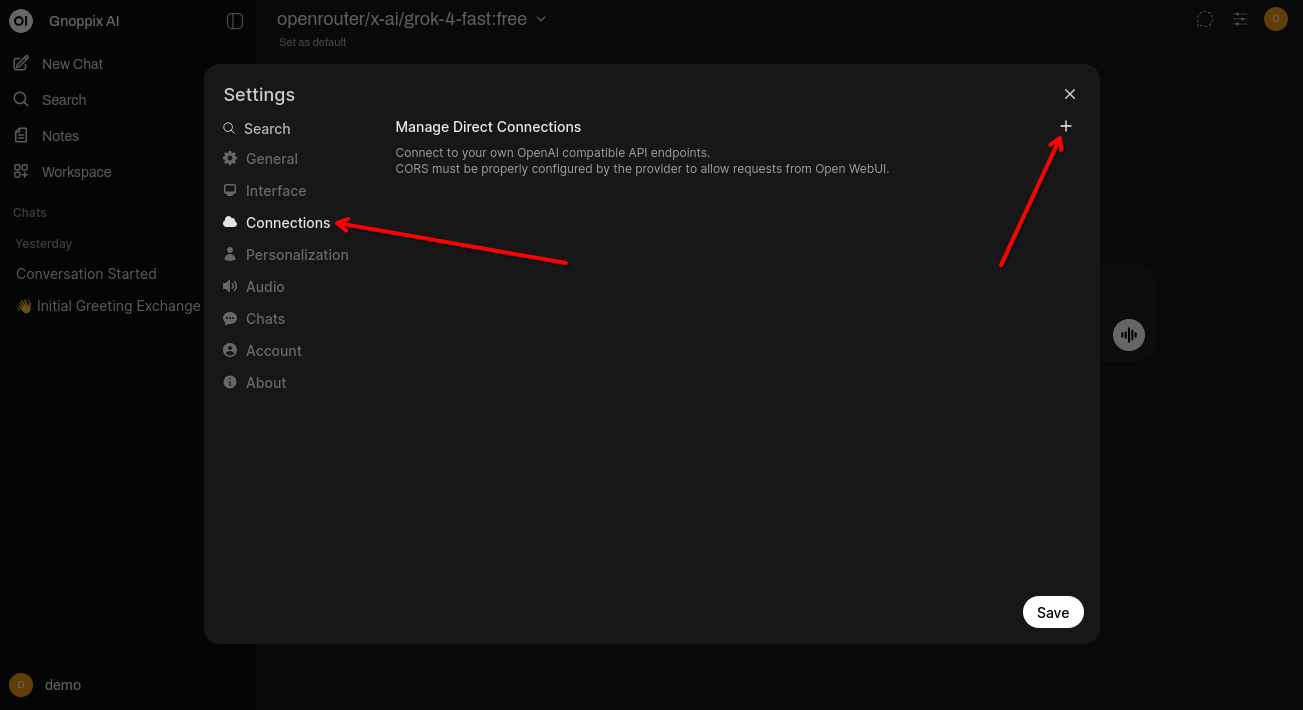
Input your own key or the given Gnoppix Member API Key.
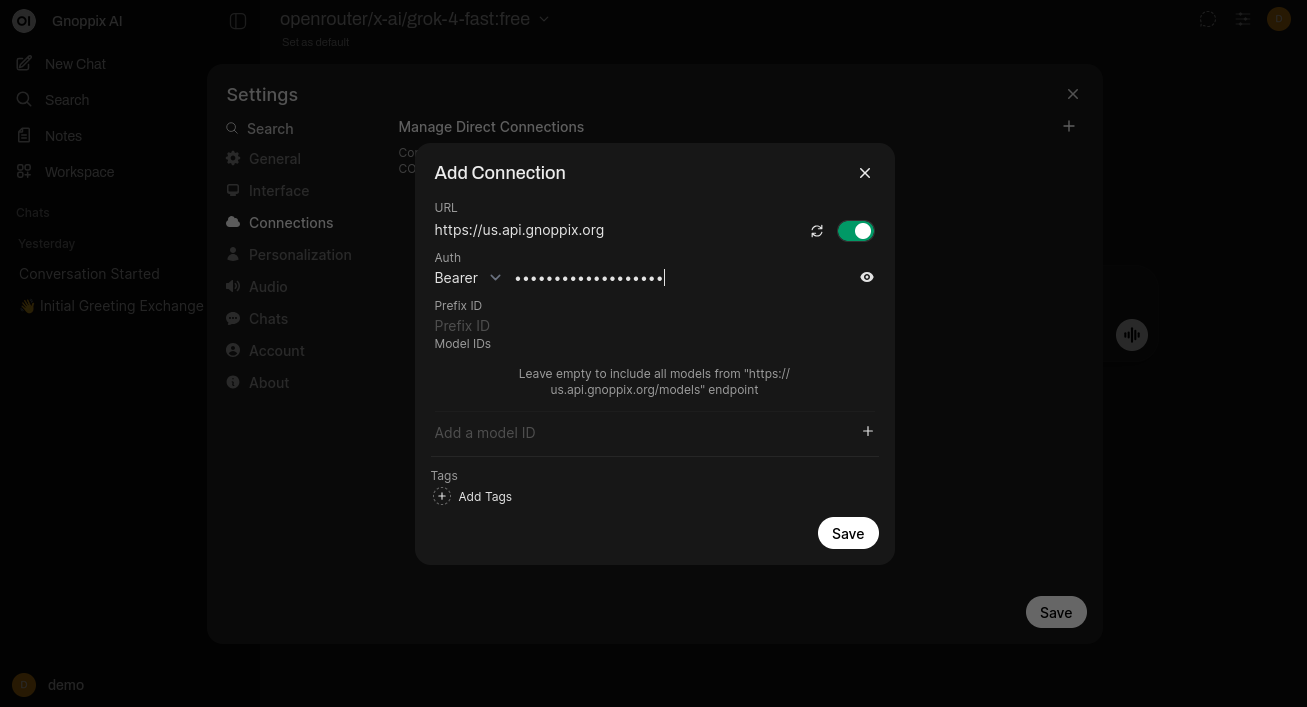
Finalise the setup
We’ve had to implement new restrictions on free accounts due to past abuse. Your access and available models now depend on your user role.
-
Normal User: If you aren’t affiliated with Gnoppix, you can use our services to test the UI. The non-CPU models are very fast. Llama 3.2, however, runs only on a CPU farm. Its speed is acceptable for demonstration purposes, but you will need to be patient.
-
Gnoppix Member: Members with a subscription have more privileges. They can use special functions and external tools, and can upload their documents for analysis.
-
Contributor: Contributors have full access to all features.
Features
Section titled “Features”✒️🔢 Full Markdown and LaTeX Support: Elevate your LLM experience with comprehensive Markdown, LaTex, and Rich Text capabilities for enriched interaction.
🧩 Model Builder: Easily create custom models from base Ollama models directly from WebUI. Create and add custom characters and agents, customize model elements, and import models effortlessly through Community integration.
📚 Local and Remote RAG Integration: Dive into the future of chat interactions and explore your documents with our cutting-edge Retrieval Augmented Generation (RAG) technology within your chats. Documents can be loaded into the Documents tab of the Workspace, after which they can be accessed using the pound key [#] before a query, or by starting the prompt with the pound key [#], followed by a URL for webpage content integration.
📄 Document Extraction: Extract text and data from various document formats including PDFs, Word documents, Excel spreadsheets, PowerPoint presentations, and more. Our advanced document processing capabilities enable seamless integration with your knowledge base, allowing for accurate retrieval and generation of information from complex documents while preserving their structure and formatting.
🔍 Web Search for RAG: You can perform web searches using a selection of various search providers and inject the results directly into your local Retrieval Augmented Generation (RAG) experience.
🌐 Web Browsing Capabilities: Integrate websites seamlessly into your chat experience by using the # command followed by a URL. This feature enables the incorporation of web content directly into your conversations, thereby enhancing the richness and depth of your interactions.
🎨 Image Generation Integration: Seamlessly incorporate image generation capabilities to enrich your chat experience with dynamic visual content.
⚙️ Concurrent Model Utilization: Effortlessly engage with multiple models simultaneously, harnessing their unique strengths for optimal responses. Leverage a diverse set of model modalities in parallel to enhance your experience.
🔐 Role-Based Access Control (RBAC): Ensure secure access with restricted permissions. Only authorized individuals can access your Ollama, while model creation and pulling rights are exclusively reserved for administrators.
🌐🌍 Multilingual Support: Experience in your preferred language with our internationalization (i18n) support. We invite you to join us in expanding our supported languages! We’re actively seeking contributors!
Pipelines Framework: Seamlessly integrate and customize your experience with our modular plugin framework for enhanced customization and functionality (https://github.com/open-webui/pipelines). Our framework allows for the easy addition of custom logic and integration of Python libraries, from AI agents to home automation APIs.
📥 Upload Pipeline: Pipelines can be uploaded directly from the Admin Panel > Settings > Pipelines menu, streamlining the pipeline management process.
The possibilities with our Pipelines framework knows no bounds and are practically limitless. Start with a few pre-built pipelines to help you get started!
🔗 Function Calling: Integrate Function Calling seamlessly through Pipelines to enhance your LLM interactions with advanced function calling capabilities.
📚 Custom RAG: Integrate a custom Retrieval Augmented Generation (RAG) pipeline seamlessly to enhance your LLM interactions with custom RAG logic.
📊 Message Monitoring with Langfuse: Monitor and analyze message interactions in real-time usage statistics via Langfuse pipeline.
⚖️ User Rate Limiting: Manage API usage efficiently by controlling the flow of requests sent to LLMs to prevent exceeding rate limits with Rate Limit pipeline.
🌍 Real-Time LibreTranslate Translation: Integrate real-time translations into your LLM interactions using LibreTranslate pipeline, enabling cross-lingual communication. Please note that this pipeline requires further setup with LibreTranslate in a Docker container to work.
🛡️ Toxic Message Filtering: Our Detoxify pipeline automatically filters out toxic messages to maintain a clean and safe chat environment.
🔒 LLM-Guard: Ensure secure LLM interactions with LLM-Guard pipeline, featuring a Prompt Injection Scanner that detects and mitigates crafty input manipulations targeting large language models. This protects your LLMs from data leakage and adds a layer of resistance against prompt injection attacks.
🕒 Conversation Turn Limits: Improve interaction management by setting limits on conversation turns with Conversation Turn Limit pipeline.
📈 OpenAI Generation Stats: Our OpenAI pipeline provides detailed generation statistics for OpenAI models.
🚀 Multi-Model Support: Our seamless integration with various AI models from various providers expands your possibilities with a wide range of language models to select from and interact with.
🖥️ Intuitive Interface: The chat interface has been designed with the user in mind, drawing inspiration from the user interface of ChatGPT.
⚡ Swift Responsiveness: Enjoy reliably fast and responsive performance.
🎨 Splash Screen: A simple loading splash screen for a smoother user experience.
🌐 Personalized Interface: Choose between a freshly designed search landing page and the classic chat UI from Settings > Interface, allowing for a tailored experience.
🌈 Theme Customization: Personalize your experience with a range of options, including a variety of solid, yet sleek themes, customizable chat background images, and three mode options: Light, Dark, or OLED Dark mode - or let Her choose for you! ;)
🖼️ Custom Background Support: Set a custom background from Settings > Interface to personalize your experience.
📝 Rich Banners with Markdown: Create visually engaging announcements with markdown support in banners, enabling richer and more dynamic content.
💻 Code Syntax Highlighting: Our syntax highlighting feature enhances code readability, providing a clear and concise view of your code.
🗨️ Markdown Rendering in User Messages: User messages are now rendered in Markdown, enhancing readability and interaction.
🎨 Flexible Text Input Options: Switch between rich text input and legacy text area input for chat, catering to user preferences and providing a choice between advanced formatting and simpler text input.
👆 Effortless Code Sharing : Streamline the sharing and collaboration process with convenient code copying options, including a floating copy button in code blocks and click-to-copy functionality from code spans, saving time and reducing frustration.
🎨 Interactive Artifacts: Render web content and SVGs directly in the interface, supporting quick iterations and live changes for enhanced creativity and productivity.
🖊️ Live Code Editing: Supercharged code blocks allow live editing directly in the LLM response, with live reloads supported by artifacts, streamlining coding and testing.
🔍 Enhanced SVG Interaction: Pan and zoom capabilities for SVG images, including Mermaid diagrams, enable deeper exploration and understanding of complex concepts.
🔍 Text Select Quick Actions: Floating buttons appear when text is highlighted in LLM responses, offering deeper interactions like “Ask a Question” or “Explain”, and enhancing overall user experience.
↕️ Bi-Directional Chat Support: You can easily switch between left-to-right and right-to-left chat directions to accommodate various language preferences.
📱 Mobile Accessibility: The sidebar can be opened and closed on mobile devices with a simple swipe gesture.
🤳 Haptic Feedback on Supported Devices: Android devices support haptic feedback for an immersive tactile experience during certain interactions.
🔍 User Settings Search: Quickly search for settings fields, improving ease of use and navigation.
📜 Offline Swagger Documentation: Access developer-friendly Swagger API documentation offline, ensuring full accessibility wherever you are.
💾 Performance Optimizations: Lazy loading of large dependencies minimizes initial memory usage, boosting performance and reducing loading times.
💬 True Asynchronous Chat: Enjoy uninterrupted multitasking with true asynchronous chat support, allowing you to create chats, navigate away, and return anytime with responses ready.
🔔 Chat Completion Notifications: Stay updated with instant in-UI notifications when a chat finishes in a non-active tab, ensuring you never miss a completed response.
🌐 Notification Webhook Integration: Receive timely updates for long-running chats or external integration needs with configurable webhook notifications, even when your tab is closed.
📚 Channels (Beta): Explore real-time collaboration between users and AIs with Discord/Slack-style chat rooms, build bots for channels, and unlock asynchronous communication for proactive multi-agent workflows.
🖊️ Typing Indicators in Channels: Enhance collaboration with real-time typing indicators in channels, keeping everyone engaged and informed.
👤 User Status Indicators: Quickly view a user’s status by clicking their profile image in channels, providing better coordination and availability insights.
💬 Chat Controls: Easily adjust parameters for each chat session, offering more precise control over your interactions.
💖 Favorite Response Management: Easily mark and organize favorite responses directly from the chat overview, enhancing ease of retrieval and access to preferred responses.
📌 Pinned Chats: Support for pinned chats, allowing you to keep important conversations easily accessible.
🔍 RAG Embedding Support: Change the Retrieval Augmented Generation (RAG) embedding model directly in the Admin Panel > Settings > Documents menu, enhancing document processing. This feature supports Ollama and OpenAI models.
📜 Citations in RAG Feature: The Retrieval Augmented Generation (RAG) feature allows users to easily track the context of documents fed to LLMs with added citations for reference points.
🌟 Enhanced RAG Pipeline: A togglable hybrid search sub-feature for our RAG embedding feature that enhances the RAG functionality via BM25, with re-ranking powered by CrossEncoder, and configurable relevance score thresholds.
📹 YouTube RAG Pipeline: The dedicated Retrieval Augmented Generation (RAG) pipeline for summarizing YouTube videos via video URLs enables smooth interaction with video transcriptions directly.
📁 Comprehensive Document Retrieval: Toggle between full document retrieval and traditional snippets, enabling comprehensive tasks like summarization and supporting enhanced document capabilities.
🌟 RAG Citation Relevance: Easily assess citation accuracy with the addition of relevance percentages in RAG results.
🗂️ Advanced RAG: Improve RAG accuracy with smart pre-processing of chat history to determine the best queries before retrieval.
📚 Inline Citations for RAG: Benefit from seamless inline citations for Retrieval-Augmented Generation (RAG) responses, improving traceability and providing source clarity for newly uploaded files.
📁 Large Text Handling: Optionally convert large pasted text into a file upload to be used directly with RAG, keeping the chat interface cleaner.
🔄 Multi-Modal Support: Effortlessly engage with models that support multi-modal interactions, including images (e.g., LLaVA).
🤖 Multiple Model Support: Quickly switch between different models for diverse chat interactions.
🔀 Merge Responses in Many Model Chat: Enhances the dialogue by merging responses from multiple models into a single, coherent reply.
✅ Multiple Instances of Same Model in Chats: Enhanced many model chat to support adding multiple instances of the same model.
💬 Temporary Chat Feature: Introduced a temporary chat feature, deprecating the old chat history setting to enhance user interaction flexibility.
🖋️ User Message Editing: Enhanced the user chat editing feature to allow saving changes without sending.
💬 Efficient Conversation Editing: Create new message pairs quickly and intuitively using the Cmd/Ctrl+Shift+Enter shortcut, streamlining conversation length tests.
🖼️ Client-Side Image Compression: Save bandwidth and improve performance with client-side image compression, allowing you to compress images before upload from Settings > Interface.
👥 ’@’ Model Integration: By seamlessly switching to any accessible local or external model during conversations, users can harness the collective intelligence of multiple models in a single chat. This can done by using the @ command to specify the model by name within a chat.
🏷️ Conversation Tagging : Effortlessly categorize and locate tagged chats for quick reference and streamlined data collection using our efficient ‘tag:’ query system, allowing you to manage, search, and organize your conversations without cluttering the interface.
🧠 Auto-Tagging: Conversations can optionally be automatically tagged for improved organization, mirroring the efficiency of auto-generated titles.
👶 Chat Cloning: Easily clone and save a snapshot of any chat for future reference or continuation. This feature makes it easy to pick up where you left off or share your session with others. To create a copy of your chat, simply click on the Clone button in the chat’s dropdown options. Can you keep up with your clones?
⭐ Visualized Conversation Flows: Interactive messages diagram for improved visualization of conversation flows, enhancing understanding and navigation of complex discussions.
📁 Chat Folders: Organize your chats into folders, drag and drop them for easy management, and export them seamlessly for sharing or analysis.
📤 Easy Chat Import: Import chats into your workspace by simply dragging and dropping chat exports (JSON) onto the sidebar.
📜 Prompt Preset Support: Instantly access custom preset prompts using the / command in the chat input. Load predefined conversation starters effortlessly and expedite your interactions. Import prompts with ease through Community integration or create your own!
🛠️ Model Builder: All models can be built and edited with a persistent model builder mode within the models edit page.
📚 Knowledge Support for Models: The ability to attach tools, functions, and knowledge collections directly to models from a model’s edit page, enhancing the information available to each model.
🗂️ Model Presets: Create and manage model presets for both the Ollama and OpenAI API.
🏷️ Model Tagging: The models workspace enables users to organize their models using tagging.
📋 Model Selector Dropdown Ordering: Models can be effortlessly organized by dragging and dropping them into desired positions within the model workspace, which will then reflect the changes in the model dropdown menu.
🔍 Model Selector Dropdown: Easily find and select your models with fuzzy search and detailed model information with model tags and model descriptions.
⌨️ Arrow Keys Model Selection: Use arrow keys for quicker model selection, enhancing accessibility.
🔧 Quick Actions in Model Workspace: Enhanced Shift key quick actions for hiding/displaying and deleting models in the model workspace.
😄 Transparent Model Usage: Stay informed about the system’s state during queries with knowledge-augmented models, thanks to visible status displays.
⚙️ Fine-Tuned Control with Advanced Parameters: Gain a deeper level of control by adjusting model parameters such as seed, temperature, frequency penalty, context length, seed, and more.
🔄 Seamless Integration: Copy any ollama run CLI command directly from a model’s page on Ollama library and paste it into the model dropdown to easily select and pull models.
🗂️ Create Ollama Modelfile: To create a model file for Ollama, navigate to the Admin Panel > Settings > Models > Create a model menu.
⬆️ GGUF File Model Creation: Effortlessly create Ollama models by uploading GGUF files directly from Huggingface or your local drive from the Admin Settings > Settings > Model > Experimental menu. The process has been streamlined with the option to upload from your machine or download GGUF files from Hugging Face.
⚙️ Default Model Setting: The default model preference for new chats can be set in the Settings > Interface menu on mobile devices, or can more easily be set in a new chat under the model selector dropdown on desktop PCs and laptops.
💡 LLM Response Insights: Details of every generated response can be viewed, including external model API insights and comprehensive local model info.
🕒 Model Details at a Glance: View critical model details, including model hash and last modified timestamp, directly in the Models workspace for enhanced tracking and management.
📥🗑️ Download/Delete Models: Models can be downloaded or deleted directly from WebUI with ease.
🔄 Update All Ollama Models: A convenient button allows users to update all their locally installed models in one operation, streamlining model management.
🍻 TavernAI Character Card Integration: Experience enhanced visual storytelling with TavernAI Character Card Integration in our model builder. Users can seamlessly incorporate TavernAI character card PNGs directly into their model files, creating a more immersive and engaging user experience.
🎲 Model Playground (Beta): Try out models with the model playground area (beta), which enables users to test and explore model capabilities and parameters with ease in a sandbox environment before deployment in a live chat environment.
👥 Collaboration
🗨️ Local Chat Sharing: Generate and share chat links between users in an efficient and seamless manner, thereby enhancing collaboration and communication.
👍👎 RLHF Annotation: Enhance the impact of your messages by rating them with either a thumbs up or thumbs down AMD provide a rating for the response on a scale of 1-10, followed by the option to provide textual feedback, facilitating the creation of datasets for Reinforcement Learning from Human Feedback (RLHF). Utilize your messages to train or fine-tune models, all while ensuring the confidentiality of locally saved data.
🔧 Comprehensive Feedback Export: Export feedback history data to JSON for seamless integration with RLHF processing and further analysis, providing valuable insights for improvement.
🤝 Community Sharing: Share your chat sessions with the Community by clicking the Share to Community button. This feature allows you to engage with other users and collaborate on the platform. To utilize this feature, please sign-in to your WebUI Community account. Sharing your chats fosters a vibrant community, encourages knowledge sharing, and facilitates joint problem-solving. Please note that community sharing of chat sessions is an optional feature. Only Admins can toggle this feature on or off in the Admin Settings > Settings > General menu.
🏆 Community Leaderboard: Compete and track your performance in real-time with our leaderboard system, which utilizes the ELO rating system and allows for optional sharing of feedback history.
⚔️ Model Evaluation Arena: Conduct blind A/B testing of models directly from the Admin Settings for a true side-by-side comparison, making it easier to find the best model for your needs.
🎯 Topic-Based Rankings: Discover more accurate rankings with our experimental topic-based re-ranking system, which adjusts leaderboard standings based on tag similarity in feedback.
📂 Unified and Collaborative Workspace : Access and manage all your model files, prompts, documents, tools, and functions in one convenient location, while also enabling multiple users to collaborate and contribute to models, knowledge, prompts, or tools, streamlining your workflow and enhancing teamwork.
📜 Chat History: Access and manage your conversation history with ease via the chat navigation sidebar. Toggle off chat history in the Settings > Chats menu to prevent chat history from being created with new interactions.
🔄 Regeneration History Access: Easily revisit and explore your entire LLM response regeneration history.
📬 Archive Chats: Effortlessly store away completed conversations you’ve had with models for future reference or interaction, maintaining a tidy and clutter-free chat interface.
📦 Export All Archived Chats as JSON: This feature enables users to easily export all their archived chats in a single JSON file, which can be used for backup or transfer purposes.
📄 Download Chats as JSON/PDF/TXT: Easily download your chats individually in your preferred format of .json, .pdf, or .txt format.
📤📥 Import/Export Chat History: Seamlessly move your chat data in and out of the platform via Import Chats and Export Chats options.
🗑️ Delete All Chats: This option allows you to permanently delete all of your chats, ensuring a fresh start.
🗣️ Voice Input Support: Engage with your model through voice interactions; enjoy the convenience of talking to your model directly. Additionally, explore the option for sending voice input automatically after 3 seconds of silence for a streamlined experience. Microphone access requires manually setting up a secure connection over HTTPS to work, or manually whitelisting your URL at your own risk.
😊 Emoji Call: Toggle this feature on from the Settings > Interface menu, allowing LLMs to express emotions using emojis during voice calls for a more dynamic interaction. Microphone access requires a secure connection over HTTPS for this feature to work.
🎙️ Hands-Free Voice Call Feature: Initiate voice calls without needing to use your hands, making interactions more seamless. Microphone access is required using a secure connection over HTTPS for this feature to work.
📹 Video Call Feature: Enable video calls with supported vision models like LlaVA and GPT-4o, adding a visual dimension to your communications. Both Camera & Microphone access is required using a secure connection over HTTPS for this feature to work.
👆 Tap to Interrupt: Stop the AI’s speech during voice conversations with a simple tap on mobile devices, ensuring seamless control over the interaction.
🎙️ Voice Interrupt: Stop the AI’s speech during voice conversations with your voice on mobile devices, ensuring seamless control over the interaction.
🔊 Configurable Text-to-Speech Endpoint: Customize your Text-to-Speech experience with configurable OpenAI-compatible endpoints for reading aloud LLM responses.
🔗 Direct Call Mode Access: Activate call mode directly from a URL, providing a convenient shortcut for mobile device users.
✨ Customizable Text-to-Speech: Control how message content is segmented for Text-to-Speech (TTS) generation requests, allowing for flexible speech output options.
🔊 Azure Speech Services Integration: Supports Azure Speech services for Text-to-Speech (TTS), providing users with a wider range of speech synthesis options.
🎚️ Customizable Audio Playback: Allows users to adjust audio playback speed to their preferences in Call mode settings, enhancing accessibility and usability.
🎵 Broad Audio Compatibility: Enjoy support for a wide range of audio file format transcriptions with RAG, including ‘audio/x-m4a’, to broaden compatibility with audio content within the platform.
🔊 Audio Compression: Experimental audio compression allows navigating around the 25MB limit for OpenAI’s speech-to-text processing, expanding the possibilities for audio-based interactions.
🗣️ Experimental SpeechT5 TTS: Enjoy local SpeechT5 support for improved text-to-speech capabilities.
🚀 Versatile, UI-Agnostic, OpenAI-Compatible Plugin Framework: Seamlessly integrate and customize Pipelines for efficient data processing and model training, ensuring ultimate flexibility and scalability.
🛠️ Native Python Function Calling: Access the power of Python directly within WebUI with native function calling. Easily integrate custom code to build unique features like custom RAG pipelines, web search tools, and even agent-like actions via a built-in code editor to seamlessly develop and integrate function code within the Tools and Functions workspace.
🐍 Python Code Execution: Execute Python code locally in the browser via Pyodide with a range of libraries supported by Pyodide.
🌊 Mermaid Rendering: Create visually appealing diagrams and flowcharts directly within WebUI using the Mermaid Diagramming and charting tool, which supports Mermaid syntax rendering.
🔗 Iframe Support: Enables rendering HTML directly into your chat interface using functions and tools.
✨ Multiple OpenAI-Compatible API Support: Seamlessly integrate and customize various OpenAI-compatible APIs, enhancing the versatility of your chat interactions.
🔑 Simplified API Key Management: Easily generate and manage secret keys to leverage WebUI with OpenAI libraries, streamlining integration and development.
🌐🔗 External Ollama Server Connectivity: Seamlessly link to an external Ollama server hosted on a different address by configuring the environment variable.
🛢️ Flexible Database Integration: Seamlessly connect to custom databases, including SQLite, Postgres, and multiple vector databases like Milvus, using environment variables for flexible and scalable data management.
🌐🗣️ External Speech-to-Text Support: The addition of external speech-to-text (STT) services provides enhanced flexibility, allowing users to choose their preferred provider for seamless interaction.
🌐 Remote ChromaDB Support: Extend the capabilities of your database by connecting to remote ChromaDB servers.
🔀 Multiple Ollama Instance Load Balancing: Effortlessly distribute chat requests across multiple Ollama instances for enhanced performance and reliability.
🚀 Advanced Load Balancing and Reliability: Utilize enhanced load balancing capabilities, stateless instances with full Redis support, and automatic web socket re-connection to promote better performance, reliability, and scalability in WebUI, ensuring seamless and uninterrupted interactions across multiple instances.
☁️ Experimental S3 Support: Enable stateless WebUI instances with S3 support for enhanced scalability and balancing heavy workloads.